Confluence connector
OAuth 2.0Project ManagementFiles & DocumentsCollaborationConnect to Confluence. Manage spaces, pages, content, and team collaboration
Confluence connector
-
Install the SDK
Section titled “Install the SDK”Terminal window npm install @scalekit-sdk/nodeTerminal window pip install scalekit -
Set your credentials
Section titled “Set your credentials”Add your Scalekit credentials to your
.envfile. Find values in app.scalekit.com > Developers > API Credentials..env SCALEKIT_ENVIRONMENT_URL=<your-environment-url>SCALEKIT_CLIENT_ID=<your-client-id>SCALEKIT_CLIENT_SECRET=<your-client-secret> -
Set up the connector
Section titled “Set up the connector”Register your Confluence credentials with Scalekit so it handles the token lifecycle. You do this once per environment.
Dashboard setup steps
Register your Scalekit environment with the Confluence connector so Scalekit handles the authentication flow and token lifecycle for you. The connection name you create will be used to identify and invoke the connection programmatically. Then complete the configuration in your application as follows:
-
Set up auth redirects
-
In Scalekit dashboard, go to AgentKit > Connections > Create Connection. Find Confluence and click Create. Copy the redirect URI. It looks like
https://<SCALEKIT_ENVIRONMENT_URL>/sso/v1/oauth/<CONNECTION_ID>/callback.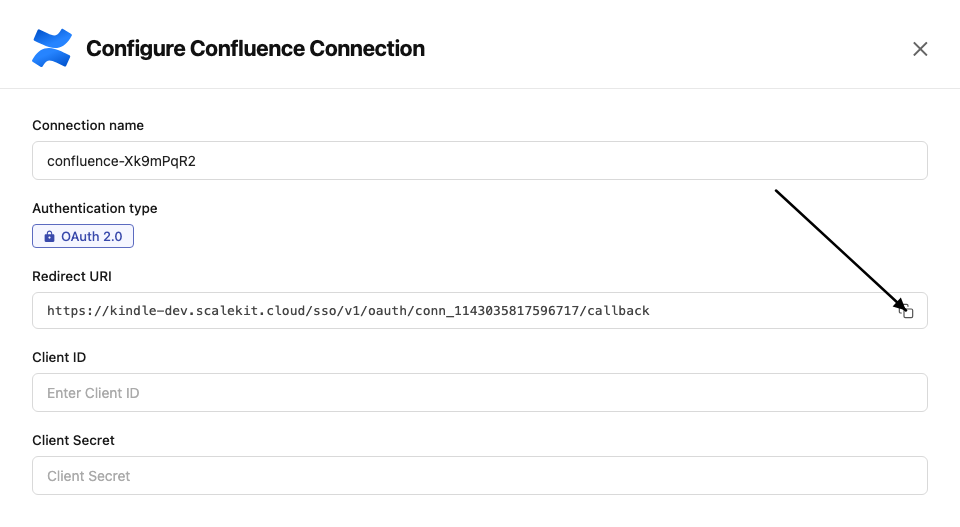
-
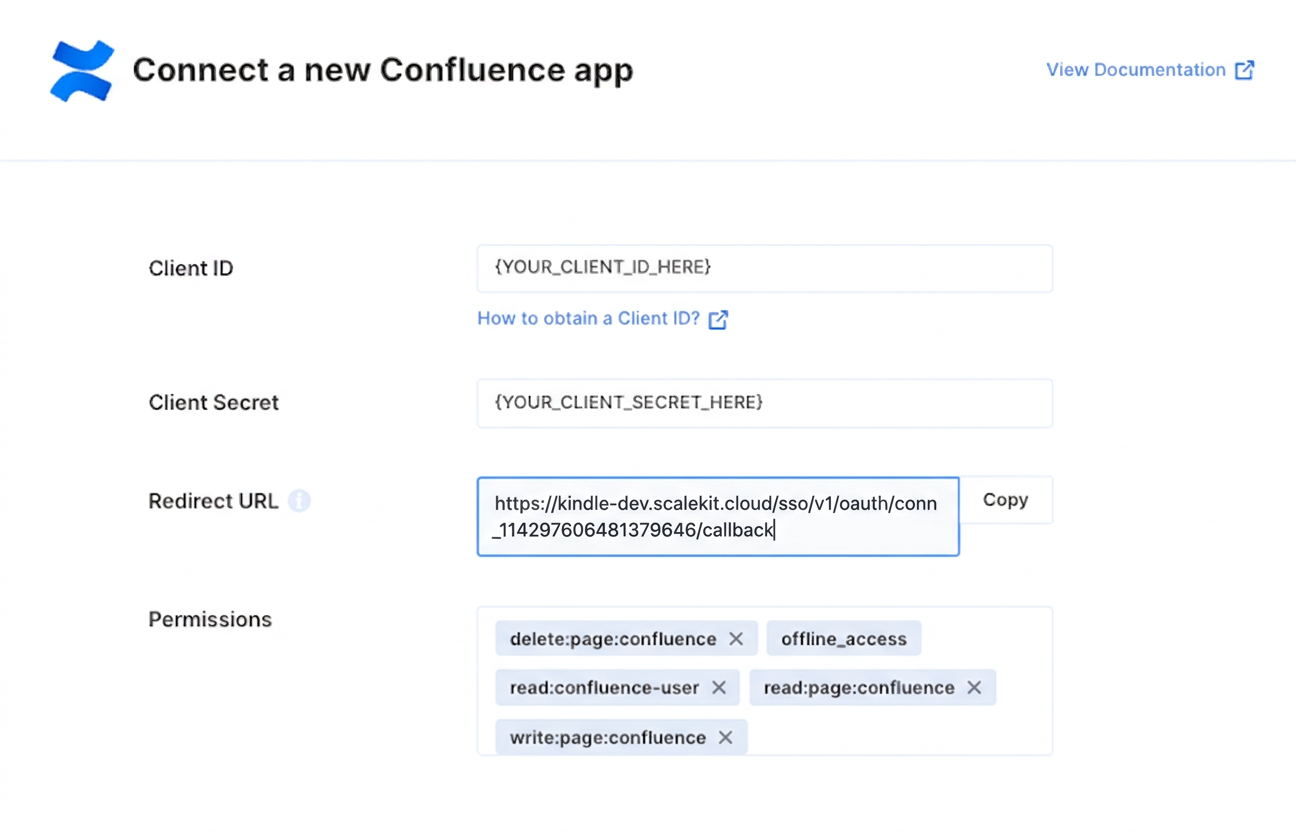
In the Atlassian Developer Console, open your app and go to Authorization → OAuth 2.0 (3LO) → Configure.
-
Paste the copied URI into the Callback URL field and click Save changes.
-
-
Get client credentials
In the Atlassian Developer Console, open your app and go to Settings:
- Client ID — listed under Client ID
- Client Secret — listed under Secret
-
Add credentials in Scalekit
-
In Scalekit dashboard, go to AgentKit > Connections and open the connection you created.
-
Enter your credentials:
- Client ID (from your Atlassian app settings)
- Client Secret (from your Atlassian app settings)
- Permissions (scopes — see Confluence OAuth scopes reference)

-
Click Save.
-
-
-
Authorize and make your first call
Section titled “Authorize and make your first call”quickstart.ts import { ScalekitClient } from '@scalekit-sdk/node'import 'dotenv/config'const scalekit = new ScalekitClient(process.env.SCALEKIT_ENV_URL,process.env.SCALEKIT_CLIENT_ID,process.env.SCALEKIT_CLIENT_SECRET,)const actions = scalekit.actionsconst connector = 'confluence'const identifier = 'user_123'// Generate an authorization link for the userconst { link } = await actions.getAuthorizationLink({ connectionName: connector, identifier })console.log('Authorize Confluence:', link)process.stdout.write('Press Enter after authorizing...')await new Promise(r => process.stdin.once('data', r))// Make your first callconst result = await actions.executeTool({connector,identifier,toolName: 'confluence_blogpost_list',toolInput: {},})console.log(result)quickstart.py import osfrom scalekit.client import ScalekitClientfrom dotenv import load_dotenvload_dotenv()scalekit_client = ScalekitClient(env_url=os.getenv("SCALEKIT_ENV_URL"),client_id=os.getenv("SCALEKIT_CLIENT_ID"),client_secret=os.getenv("SCALEKIT_CLIENT_SECRET"),)actions = scalekit_client.actionsconnection_name = "confluence"identifier = "user_123"# Generate an authorization link for the userlink_response = actions.get_authorization_link(connection_name=connection_name,identifier=identifier,)print("Authorize Confluence:", link_response.link)input("Press Enter after authorizing...")# Make your first callresult = actions.execute_tool(tool_input={},tool_name="confluence_blogpost_list",connection_name=connection_name,identifier=identifier,)print(result)
What you can do
Section titled “What you can do”Connect this agent connector to let your agent:
- List space, page, blogpost — List Confluence spaces accessible to the authenticated user
- Get space, page labels, page — Retrieve details of a specific Confluence space by its ID
- Search records — Search Confluence content using Confluence Query Language (CQL)
- Update page — Update an existing Confluence page
- Delete page — Delete a Confluence page by its ID
- Create page, footer comment, blogpost — Create a new Confluence page in a specified space
Common workflows
Section titled “Common workflows”Proxy API call
Don’t worry about the Confluence cloud ID in the path. Scalekit automatically resolves {{cloud_id}} from the connected account’s configuration. For example, a request with path="/wiki/rest/api/user/current" will be sent to https://api.atlassian.com/ex/confluence/a1b2c3d4-e5f6-7890-abcd-ef1234567890/wiki/rest/api/user/current automatically.
const result = await actions.request({ connectionName: 'confluence', identifier: 'user_123', path: '/wiki/rest/api/user/current', method: 'GET',});console.log(result);result = actions.request( connection_name='confluence', identifier='user_123', path="/wiki/rest/api/user/current", method="GET")print(result)Execute a tool
const result = await actions.executeTool({ connector: 'confluence', identifier: 'user_123', toolName: 'confluence_list', toolInput: {},});console.log(result);result = actions.execute_tool( tool_input={}, tool_name='confluence_list', connection_name='confluence', identifier='user_123',)print(result)Tool list
Section titled “Tool list”Use the exact tool names from the Tool list below when you call execute_tool. If you’re not sure which name to use, list the tools available for the current user first.
confluence_blogpost_create#Create a new blog post in a Confluence space. Requires a target space ID and a title. Optionally set the status (published or draft) and provide body content in storage or atlas_doc_format representation. Set the private query parameter to restrict visibility.6 params
Create a new blog post in a Confluence space. Requires a target space ID and a title. Optionally set the status (published or draft) and provide body content in storage or atlas_doc_format representation. Set the private query parameter to restrict visibility.
spaceIdstringrequiredThe ID of the space to create the blog post intitlestringrequiredTitle of the blog postbody_representationstringoptionalStorage format of the body contentbody_valuestringoptionalThe content of the blog post bodyprivatebooleanoptionalWhether to create the blog post as privatestatusstringoptionalPublication status of the blog postconfluence_blogpost_get#Retrieve a specific Confluence blog post by its ID. Returns the blog post content, metadata, author, space, status, and version history. Optionally include body content in a specified format, fetch a draft version, or a historical version.5 params
Retrieve a specific Confluence blog post by its ID. Returns the blog post content, metadata, author, space, status, and version history. Optionally include body content in a specified format, fetch a draft version, or a historical version.
idstringrequiredThe numeric ID of the blog post to retrievebody_formatstringoptionalFormat of the blog post body to include in the responseget_draftbooleanoptionalWhether to retrieve the draft version of the blog postinclude_labelsbooleanoptionalWhether to include labels applied to the blog postversionintegeroptionalVersion number of the blog post to retrieveconfluence_blogpost_list#List blog posts in Confluence. Filter by blog post IDs, space IDs, sort order, status, title, or body format. Returns paginated results with cursor-based navigation.8 params
List blog posts in Confluence. Filter by blog post IDs, space IDs, sort order, status, title, or body format. Returns paginated results with cursor-based navigation.
body_formatstringoptionalFormat of the blog post body to returncursorstringoptionalCursor token for fetching the next page of resultsidarrayoptionalFilter by specific blog post IDslimitintegeroptionalMaximum number of blog posts to return per pagesortstringoptionalSort order for the resultsspace_idarrayoptionalFilter blog posts by space IDsstatusstringoptionalFilter blog posts by statustitlestringoptionalFilter blog posts by title (partial match)confluence_page_attachments_get#Retrieve all attachments on a Confluence page. Returns a paginated list of attachments with metadata including filename, media type, file size, and download URL. Supports filtering by media type or filename and cursor-based pagination.6 params
Retrieve all attachments on a Confluence page. Returns a paginated list of attachments with metadata including filename, media type, file size, and download URL. Supports filtering by media type or filename and cursor-based pagination.
idstringrequiredThe ID of the page whose attachments to retrievecursorstringoptionalCursor token for pagination, returned in the previous response as _links.nextfilenamestringoptionalFilter attachments by exact filenamelimitintegeroptionalMaximum number of attachments to return per page (default 25, max 250)media_typestringoptionalFilter attachments by MIME media type (e.g. image/png, application/pdf)sortstringoptionalSort order for attachments (e.g. created-date, -created-date, modified-date, -modified-date)confluence_page_children_get#Retrieve the direct child pages of a given Confluence page. Returns a paginated list of child pages with their IDs, titles, and statuses. Use cursor-based pagination to iterate through large result sets.4 params
Retrieve the direct child pages of a given Confluence page. Returns a paginated list of child pages with their IDs, titles, and statuses. Use cursor-based pagination to iterate through large result sets.
idstringrequiredThe ID of the parent page whose children to retrievecursorstringoptionalCursor token for pagination, returned in the previous response as _links.nextlimitintegeroptionalMaximum number of child pages to return (default 25, max 250)sortstringoptionalSort order for child pages (e.g. -modified-date, id, title, -title)confluence_page_create#Create a new Confluence page in a specified space. Requires a space ID and title. Optionally set the initial status (current for published, draft for unpublished), a parent page, and body content. The body requires both body_representation and body_value to be provided together.8 params
Create a new Confluence page in a specified space. Requires a space ID and title. Optionally set the initial status (current for published, draft for unpublished), a parent page, and body content. The body requires both body_representation and body_value to be provided together.
spaceIdstringrequiredThe ID of the space in which to create the pagetitlestringrequiredTitle of the new pagebody_representationstringoptionalThe markup format for the page body (e.g. storage, atlas_doc_format). Must be set together with body_value.body_valuestringoptionalThe raw content of the page body in the format specified by body_representation. Must be set together with body_representation.parentIdstringoptionalID of the parent page under which this page will be createdprivatebooleanoptionalSet to true to create the page as a private page visible only to the creatorroot_levelbooleanoptionalSet to true to create the page at the root level of the space (no parent)statusstringoptionalInitial status of the page: current (published) or draft (unpublished)confluence_page_delete#Delete a Confluence page by its ID. By default moves the page to the trash; set purge=true to permanently delete without recovery. Set draft=true to delete a draft version instead of the published page. This action is irreversible when purge is enabled.3 params
Delete a Confluence page by its ID. By default moves the page to the trash; set purge=true to permanently delete without recovery. Set draft=true to delete a draft version instead of the published page. This action is irreversible when purge is enabled.
idstringrequiredThe ID of the page to deletedraftbooleanoptionalSet to true to delete the draft version of the page rather than the published versionpurgebooleanoptionalSet to true to permanently delete the page, bypassing the trashconfluence_page_get#Retrieve a single Confluence page by its ID. Returns the page title, status, version, space, and optionally the full body content. Use body_format to control the markup format returned. Additional flags expose labels, properties, and version history.7 params
Retrieve a single Confluence page by its ID. Returns the page title, status, version, space, and optionally the full body content. Use body_format to control the markup format returned. Additional flags expose labels, properties, and version history.
idstringrequiredThe ID of the page to retrievebody_formatstringoptionalFormat for the returned page body (e.g. storage, atlas_doc_format, anonymous_export_view)get_draftbooleanoptionalSet to true to retrieve the draft version of the page instead of the published versioninclude_labelsbooleanoptionalSet to true to include labels attached to the page in the responseinclude_propertiesbooleanoptionalSet to true to include content properties attached to the pageinclude_versionbooleanoptionalSet to true to include full version details in the responseversionintegeroptionalSpecific version number of the page to retrieve (defaults to latest)confluence_page_labels_get#Retrieve all labels attached to a Confluence page. Labels can be filtered by prefix (e.g. global, my, team). Returns a paginated list of label names and prefixes. Use cursor-based pagination for pages with many labels.5 params
Retrieve all labels attached to a Confluence page. Labels can be filtered by prefix (e.g. global, my, team). Returns a paginated list of label names and prefixes. Use cursor-based pagination for pages with many labels.
idstringrequiredThe ID of the page whose labels to retrievecursorstringoptionalCursor token for pagination, returned in the previous response as _links.nextlimitintegeroptionalMaximum number of labels to return per page (default 25, max 250)prefixstringoptionalFilter labels by prefix (e.g. global, my, team, system)sortstringoptionalSort order for labels (e.g. created-date, -created-date, name, -name)confluence_page_list#List Confluence pages with optional filtering by space, status, title, or page IDs. Returns a paginated collection of pages. Use the cursor parameter to fetch subsequent pages. Supports body format selection for inline content retrieval.8 params
List Confluence pages with optional filtering by space, status, title, or page IDs. Returns a paginated collection of pages. Use the cursor parameter to fetch subsequent pages. Supports body format selection for inline content retrieval.
body_formatstringoptionalThe content format to return for page bodies (e.g. storage, atlas_doc_format, anonymous_export_view)cursorstringoptionalCursor token for pagination, returned in previous response as _links.nextidstringoptionalFilter by one or more page IDs (comma-separated or repeated query param)limitintegeroptionalMaximum number of pages to return per page (default 25, max 250)sortstringoptionalSort order for results (e.g. -modified-date, id, title, -title)space_idstringoptionalFilter by one or more space IDs (comma-separated)statusstringoptionalFilter pages by status (e.g. current, archived, deleted, trashed)titlestringoptionalFilter pages by title (exact match)confluence_page_update#Update an existing Confluence page. Requires the page ID, current status, title, and the next version number (must be exactly current version + 1). Optionally update the page body, change the parent, or add a version message. Retrieve the current version number with the Get Page tool before calling this.8 params
Update an existing Confluence page. Requires the page ID, current status, title, and the next version number (must be exactly current version + 1). Optionally update the page body, change the parent, or add a version message. Retrieve the current version number with the Get Page tool before calling this.
idstringrequiredThe ID of the page to updatestatusstringrequiredStatus of the page after the update (e.g. current, draft)titlestringrequiredUpdated title of the pageversion_numberintegerrequiredThe new version number for this update. Must be exactly the current version number plus 1.body_representationstringoptionalFormat for the updated body content (e.g. storage, atlas_doc_format). Must be set together with body_value.body_valuestringoptionalThe updated body content in the format specified by body_representation. Must be set together with body_representation.parentIdstringoptionalID of the new parent page (to move the page in the hierarchy)version_messagestringoptionalOptional message describing what changed in this versionconfluence_search#Search Confluence content using Confluence Query Language (CQL). CQL is a powerful structured query language for finding pages, blog posts, spaces, attachments, and comments. Returns matching content with metadata including title, space, author, and last modified date.5 params
Search Confluence content using Confluence Query Language (CQL). CQL is a powerful structured query language for finding pages, blog posts, spaces, attachments, and comments. Returns matching content with metadata including title, space, author, and last modified date.
cqlstringrequiredConfluence Query Language (CQL) query stringcursorstringoptionalCursor token for fetching the next page of resultsexcerptstringoptionalControls excerpt handling in search resultsexpandstringoptionalComma-separated list of properties to expand in resultslimitintegeroptionalMaximum number of results to returnconfluence_space_get#Retrieve details of a specific Confluence space by its ID. Returns space metadata including key, name, type, status, description, homepage, and permissions. Optionally include the space icon and labels.4 params
Retrieve details of a specific Confluence space by its ID. Returns space metadata including key, name, type, status, description, homepage, and permissions. Optionally include the space icon and labels.
idstringrequiredThe numeric ID of the space to retrievedescription_formatstringoptionalFormat for the space description in the responseinclude_iconbooleanoptionalWhether to include the space icon in the responseinclude_labelsbooleanoptionalWhether to include labels applied to the spaceconfluence_space_list#List Confluence spaces accessible to the authenticated user. Supports filtering by space IDs, keys, type (global or personal), status (current or archived), and labels. Returns paginated results with cursor-based navigation.9 params
List Confluence spaces accessible to the authenticated user. Supports filtering by space IDs, keys, type (global or personal), status (current or archived), and labels. Returns paginated results with cursor-based navigation.
cursorstringoptionalCursor token for fetching the next page of resultsdescription_formatstringoptionalFormat for the space description in the responseidsarrayoptionalFilter spaces by their numeric IDskeysarrayoptionalFilter spaces by their space keyslabelsarrayoptionalFilter spaces by labelslimitintegeroptionalMaximum number of spaces to return per pagesortstringoptionalSort order for the resultsstatusstringoptionalFilter spaces by statustypestringoptionalFilter spaces by type